
Rise of Large Language Model Operations
A Guide to Deployment and Management of LLMs in the ML Ecosystem

The growth of Generative AI models such as LLMs in the ML ecosystem will give many advantages from productivity improvements with tools such as Github Copilot in various sectors in the coming years. Along with it comes new challenges in managing and deploying these models in production.
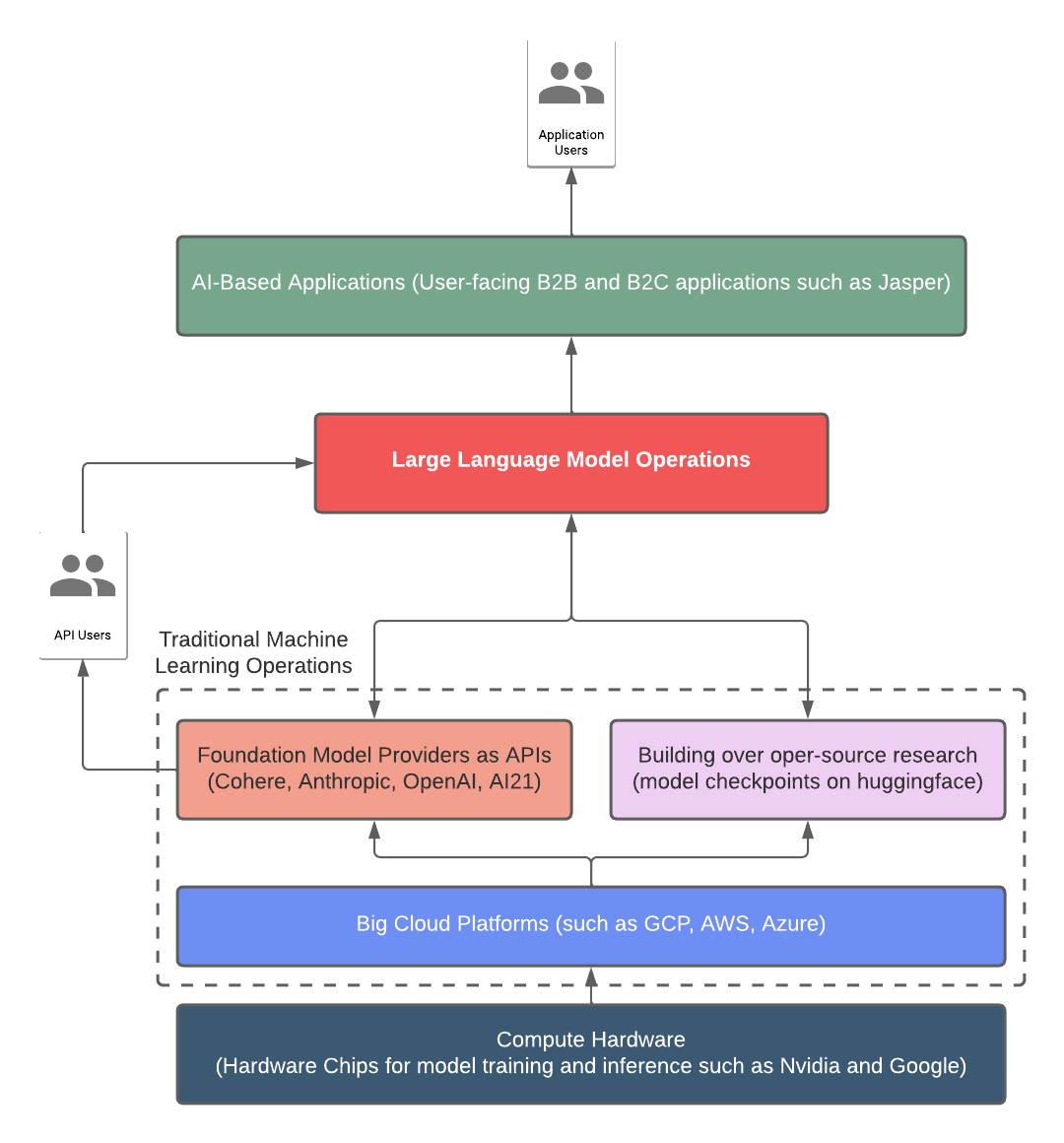
Traditionally, MLOps is the practice of integrating machine learning into the software development lifecycle, including developing, testing, deploying, and managing machine learning models. It covers the entire life cycle of a machine learning model, from development to production.
Large Language Model Operations, on the other hand, is an additional subfield of MLOps that focuses on managing and deploying large language models, such as the GPT-3 or FLAN-T5 model. LLMOps involve the management of language models at scale, including data augmentation, memory, and performance monitoring. It needs the development of specialized tools to support the operations of large language models in production.
This blog post presents architectural blueprints that encompass major use cases. Use cases covered here include text generation, search, and summarization. Those building on these APIs or internal LLM models need to manage the lifecycle of language models. Additional tooling will be necessary as the adoption of these models increases.
Text Generation
Developing prompts for language models is an iterative process similar to feature engineering. This stage involves creating prompt metadata that includes user-defined parameters and external data augmentation. You can refine the outputs from the language model through multiple iterations on prompts. This iteration can utilize versioning tools, such as mlflow, to keep track of the progress. Further refinement of the Language Model may be necessary based on its outputs. The parameters utilized for creating optimal prompts should be pushed into a prompt registry for future utilization during deployment.
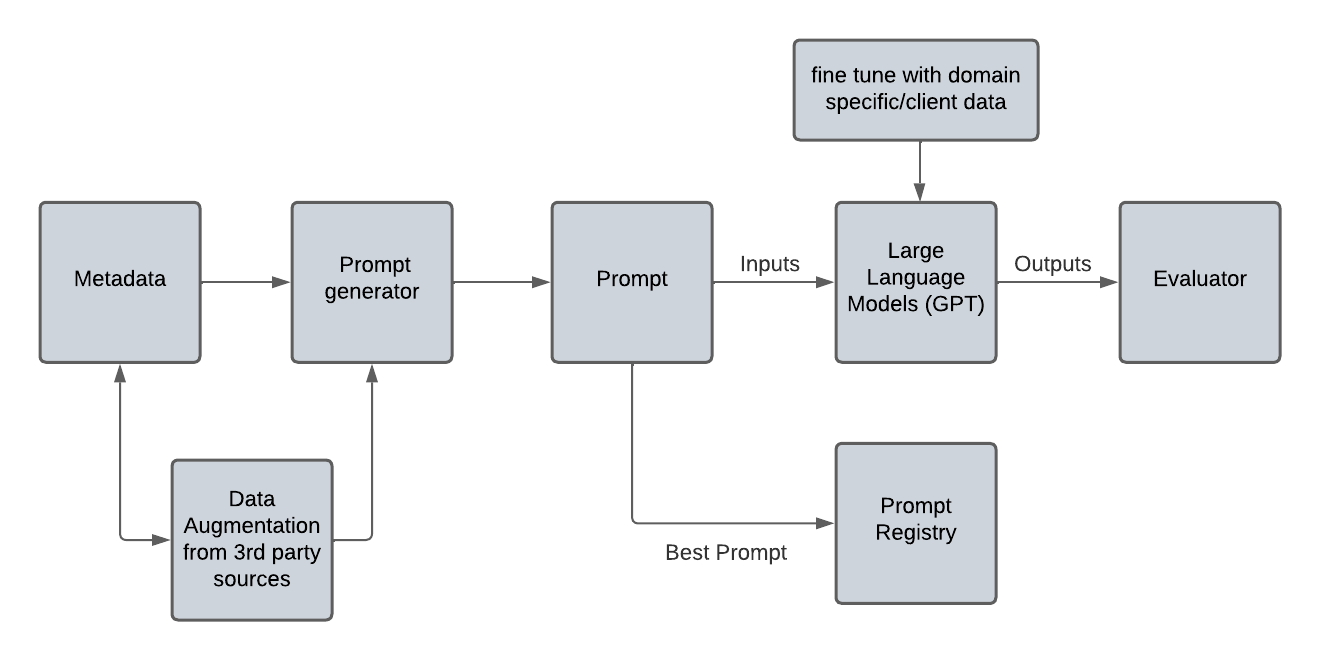
The process of text generation, after storing the relevant prompts in the registry and utilizing the finalized language model, can be carried out in the following steps:
The user inputs necessary metadata, which the application can then combine with information from external sources to create the optimal prompt.
The application can also retrieve additional meta information from the prompt artifact storage, similar to model artifact storage in production systems. Retrieval may utilize embedding similarity.
The prompt generator creates a prompt, which acts as an initial input for the language models to generate text. The generated text may be sufficient for the user's needs.
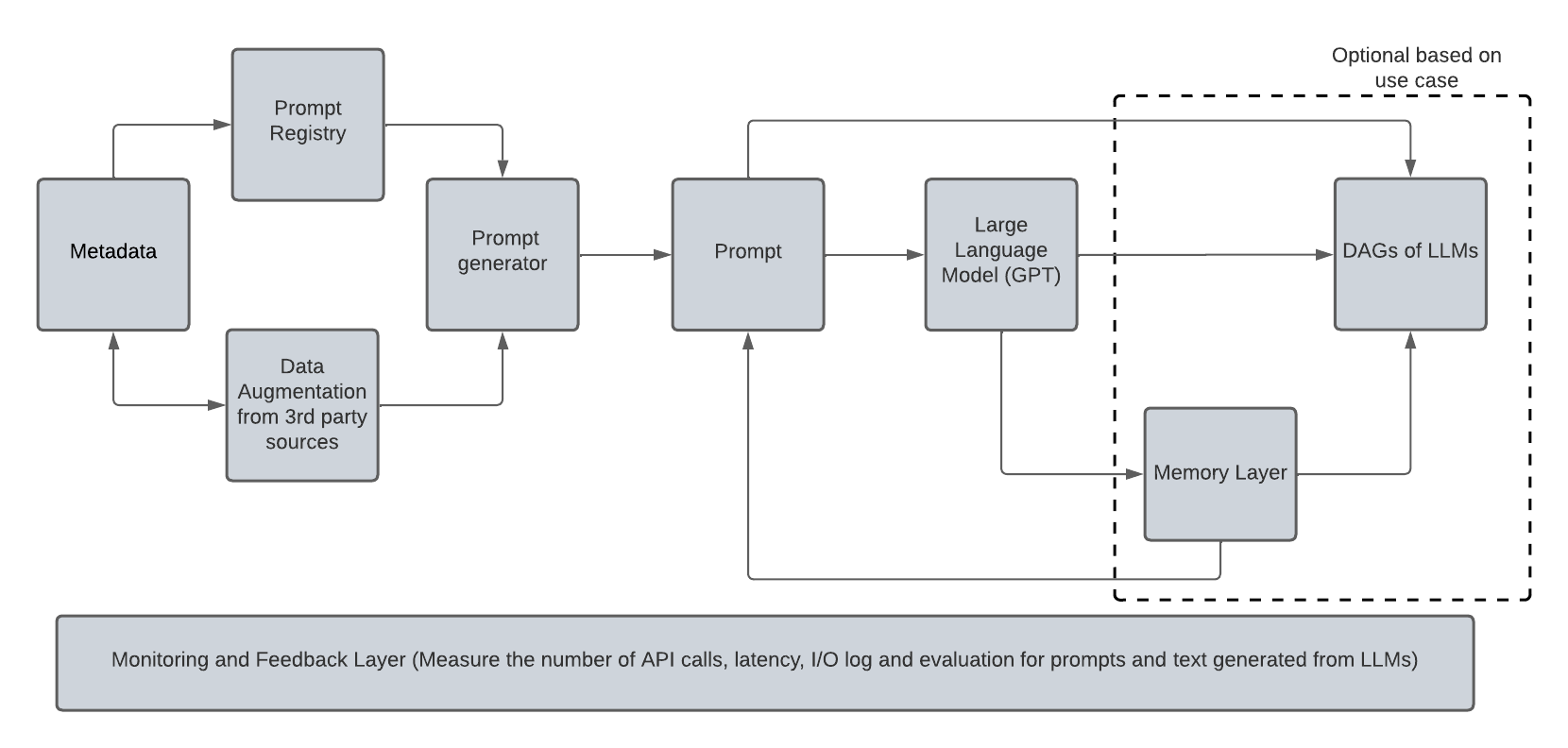
Advanced text generation is achieved through integrating various language models in Directed Acyclic Graphs (DAGs) with memory capabilities, resulting in the generation of context-sensitive text.
Although the application can function as a standalone solution, it also requires a monitoring and feedback layer to monitor and evaluate system and natural language performance metrics.

Text Generation System Architecture
Search and Summarization
In NLP, single and double-tower encoder architectures are used to convert textual information into numerical vector representations.
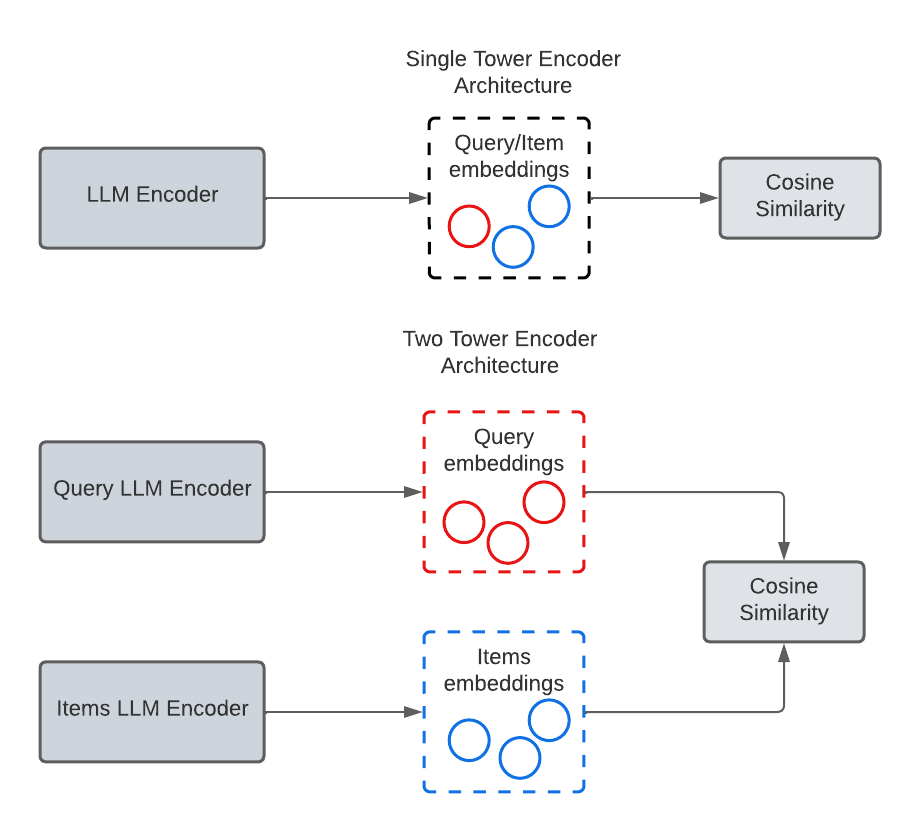
A single tower encoder has a single transformer architecture that processes input data in one pass, encoding the items and queries into a concise vector embedding. The computation of similarity between items and queries is crucial in determining the relevance between items and queries. In this setup, relevance scoring is straightforward and can be done using cosine similarity or Euclidean distance.
In contrast, a double tower encoder has a two-part architecture that processes input data in two stages. Each tower encodes the items and queries into vectors in different latent space. This design is more complex than a single tower encoder but can provide more detailed information about the item and query data. The method of computing similarity between the two vector representations can vary based on the task and architectures. Similarity score in this setup can be done by training the model to predict the similarity between items and queries in a supervised manner.
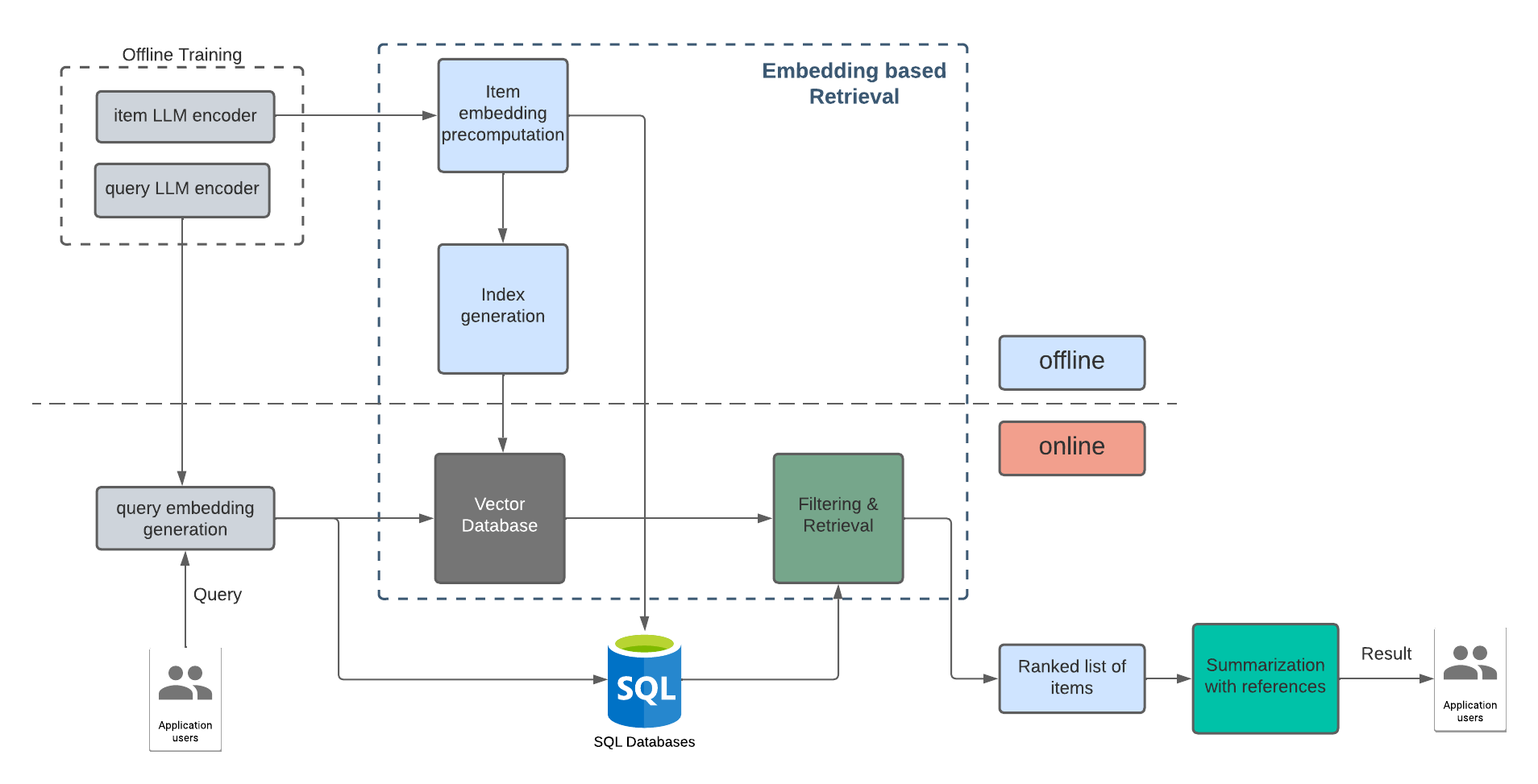
The vector embeddings of all textual information for items can be generated offline regularly and stored in vector databases. The text data can also be stored in databases such as postgres or elasticsearch.
As a search system, the application can filter results using both the textual information and the similarity scores between query and item embeddings, creating a semantic search system. The results are then ranked based on their similarity score, making a prioritized list of relevant search results.
Beyond that, the top-ranked result can be combined and used as a prompt to generate a summary answer to the user's query, providing relevant references from the indexed storage.
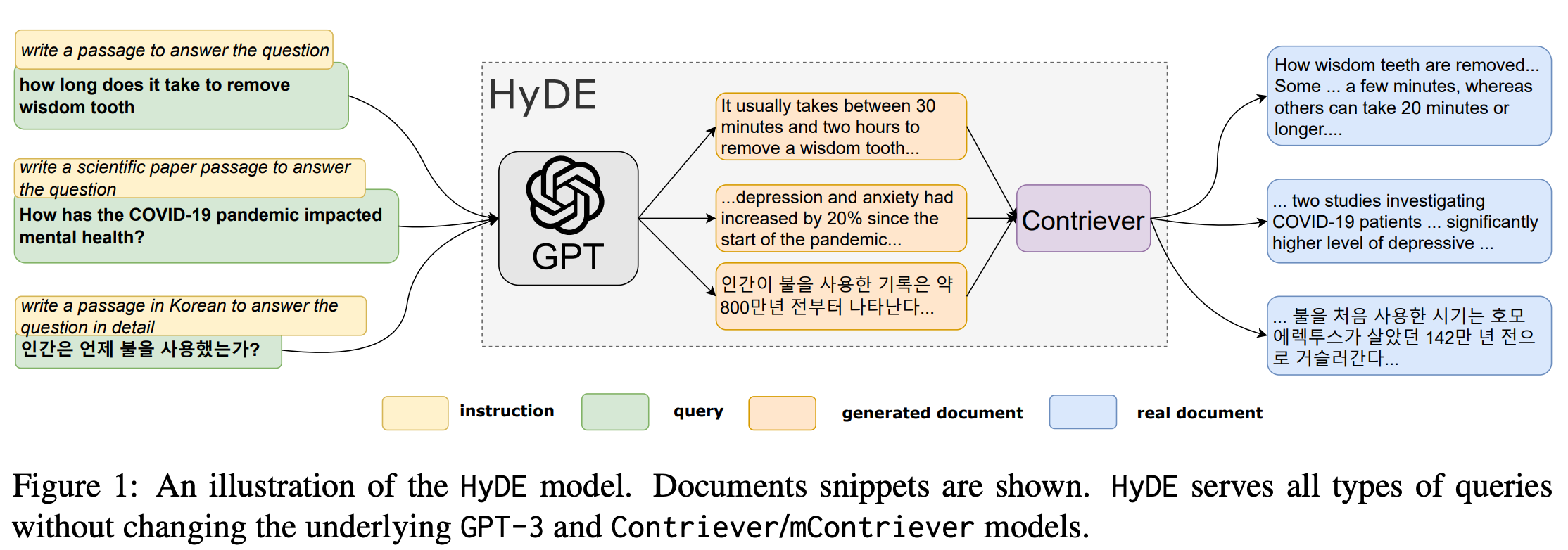
A recent paper suggests incorporating Hypothetical Document Embeddings (HyDE) into the current architecture, rather than using embeddings for the query. The HyDE approach involves instructing a language model to generate a hypothetical document that captures relevance patterns, even though it may contain false details. This hypothetical document is then encoded into a vector embedding, which is used to identify a neighborhood in the corpus embedding space and retrieve similar real documents based on vector similarity. With its promising results, it is likely that production systems could also start adopting this approach in the future.
In summary, the proliferation of Generative AI models like LLMs in the ML space brings exciting prospects for boosting productivity in various industries. However, deploying and managing these models also presents new challenges that require specific tools and techniques, such as Large Language Model Operations (LLMops). This branch of MLOps concentrates on handling large language models at scale, including creating tools for deployment in production. The field is still in its infancy, and further development of production-grade tools is needed to support LLMops and fully realize the benefits of these models.
I would like to express my appreciation to Anand Sampat, Mohamed El-Geish, and Qasim Munye for their review and input on this blog.